








シングルセルデータ解析(scRNA-seq)を容易にし、深くて新しい洞察をもたらすソリューションをご紹介します。弊社の認定キュレーターチームは、何百のシングルセルプロジェクトを手作業でキュレートし、正確にキュレートされた何千ものセルクラスターを生成しています。70以上のメタデータ属性のいずれかを使用して、数百万の細胞にアクセスし、検索できます。複数のプロジェクト間で比較し、探しているデータを簡単に見つけ出し、発見と検証を加速できます。

QIAGENの科学者は、Single Cell Land の各データセットのプロジェクト、サンプル、細胞タイプのメタデータを手作業でキュレートします。これにより、実験の生物学的背景の理解に必要なレベルの詳細な情報が、scRNAシークエンスデータに付加されます。 データセットは、統一されたワークフローを用いて生データから細心の注意を払って再処理され、徹底したQCチェックを受けた後、シングルセルの解像度で70を超える属性がアノテーションされます。 これにより、すべてのプロジェクトで特定の細胞型、組織、遺伝子、年齢、性別、またはその他のキュレートした特性を検索し、関連するデータセットをすばやく見つけることができます。

OmicSoft Single Cell Land を使用すると、一貫した再現性のある方法で、プロジェクト全体のscRNA-seq データを検索し、比較できます。遺伝子、組織、疾患、細胞型、またはその他の70を超えるメタデータ属性のいずれかのレベルで検索できます。Single Cell Landフレームワークは、プロジェクト間のデータを可視化するために設計されています。これにより、これまで考慮していなかったプロジェクトで潜在的バイオマーカーを探索し、新しい細胞型、病状、発生段階、または実験状態での発現を検出できます。
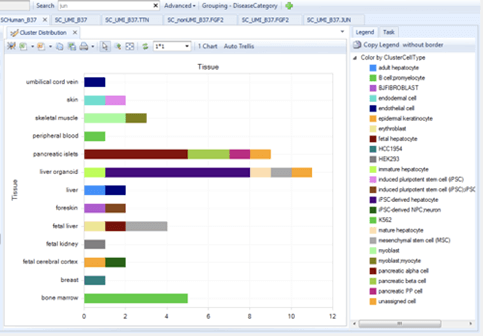
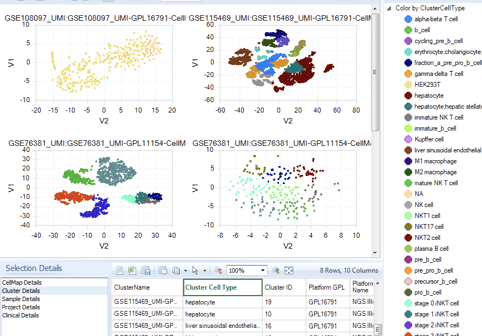
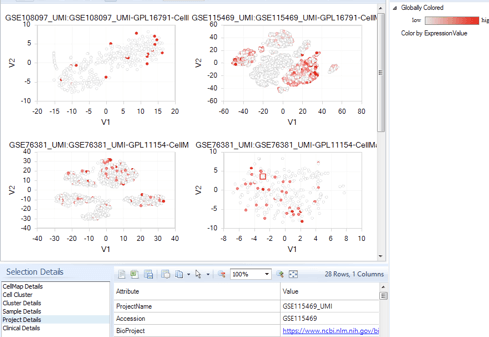
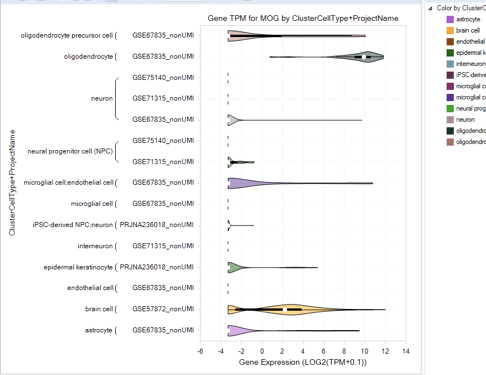
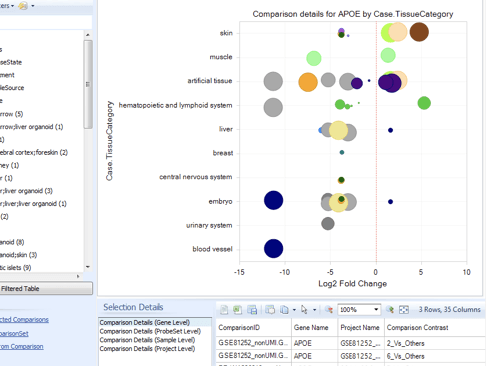
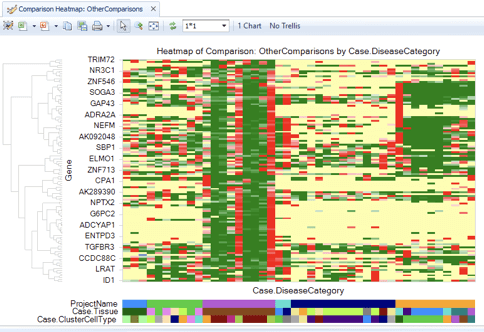
OmicSoft Single Cell Land は、インタラクティブな可視化機能とエクスポート可能な詳細情報により、重要なインサイト抽出に必要なツールと可視化機能を提供します。tSNEまたはUMAPプロット、発現分布プロットまたはバイオリンプロット、セルクラスタープロット、ヒートマップなどを介して、次元削減の結果を見つけられます。 OmicSoft Single Cell Landは、外部ツールとの互換性のために、オープンスタンダードのh5ad形式でのシングルセルデータのエクスポートもサポートしています。

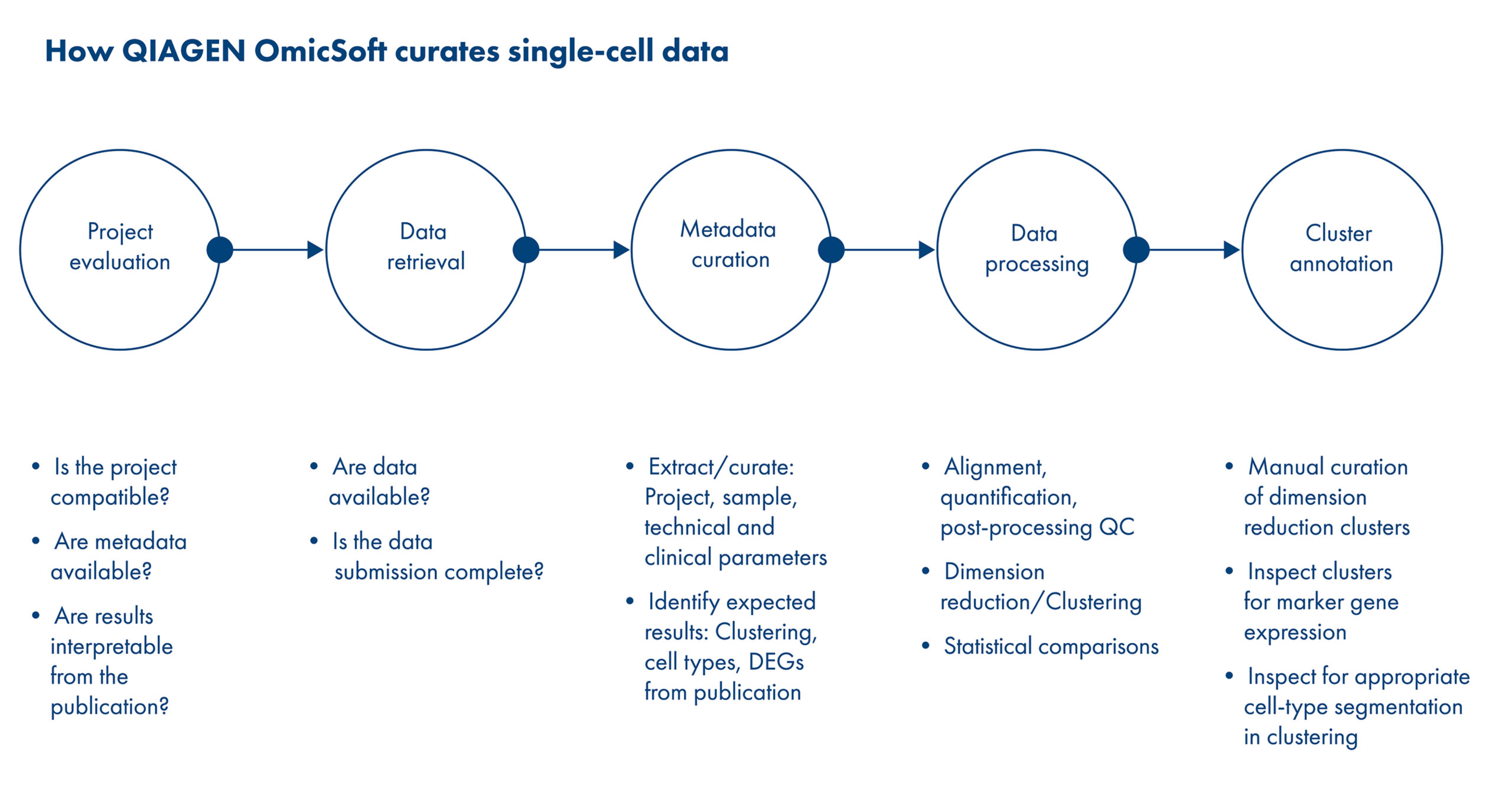
キュレーションは、データを FAIR(検索可能、アクセス可能、相互運用可能、再利用可能)にするための基盤です。QIAGENでは、50名以上の Ph.D.、M.S.、M.D. の認定キュレーターからなるチームが高品質で信頼性の高いデータを確保するために、厳格なプロトコルに従ってデータのキュレーションを行っています。scRNA-seq データの標準キュレーション法は、QIAGEN OmicSoft OncoLand およびDiseaseLand と同一であるため、発見したデータをすばやくバルクの細胞実験から1細胞の解像度まで精査することができます。細胞型までの手作業によるキュレーションで、研究に関連するデータセットを見つけられます。細胞クラスター間の事前計算された比較によって、重要な細胞型のシグネチャーが明らかになり、すぐに実験へ応用できます。

If you are a data scientist focused on ‘omics analysis, you’re probably consumed by maintaining your data lake and structuring the specific data you need. You may be frustrated by the gaps and inconsistencies in dataset metadata that cause your queries to return misleading results that could negatively impact your research.
With API access to QIAGEN OmicSoft data, you no longer must find, ingest and maintain databases that contain aggregations of public ‘omics data riddled with inconsistencies. Instead, you’ll be empowered to get right to the data analysis with queries of small or huge data slices from our unified ‘omics database. Our rigorous metadata curation approach combined with API access to structured and integrated ‘omics data allows you to perform large and complex cross-database, multi-omics queries. We also offer flat file options for ingesting the data into your own database or through our GUI designed for ‘omics visualization.






